Each challenge is a chance to explore new ML/AI methods with guidance from advisors and support from your peers. You don’t need to be an expert for your selected challenge—but you do want to pick something where you can grow while still contributing meaningfully to your team. Look for a challenge that’s in your zone of capability, not so far out that it becomes overwhelming. Challenge prerequisites can help you gauge fit, but what really matters is finding teammates who share your pace, interests, and learning goals.
Minimum requirements: All MLM25 participants are expected to know Python, machine learning fundamentals, and GitHub (enough to collaborate). If you need to get up to speed, please complete the relevant self-paced workshop(s) prior to kickoff: Intro Python, Collaborating with GitHub Desktop, and/or Intro to Machine Learning.
Challenges
- Advanced Reasoning Corpus (ARC) 2025
- Brain-to-Text
- Cellular State Image Analysis
- Clustering the BioTrove Dataset
- CrisisCompanion: Creating a Mental Health Support Chatbot
- Digit Recognizer: Deep Learning Intro
- MaveDB Amino Acid Substitution
- SurveyResponder Statistics
- Store Sales: Time Series Forecasting
- WattBot: Estimating AI Emissions with RAG
Find Team Members
Once you’ve identified a challenge that suits your interests and learning goals, head to the MLM25 Slack channel (you may need to join the Data Science Hub Slack first) to start connecting with others. In your message, be sure to include:
- Your goal(s) for participating in MLM25
- Your preferred challenge(s)
-
Any previous ML/AI experience (all experience levels welcome—just be mindful of challenge prerequisites)
-
How many hours/week you realistically expect to commit, including fall semester adjustments
Additional Networking Opportunities
In addition to Slack and our kickoff event on 9/11, you can meet potential teammates and learn more about challenges at the following ML+X events.
- AI’s Environmental Footprint (9/9): This event is on Zoom, but will include a short WattBot challenge preview.
- ML+Coffee (9/10): MLM25 participants are invited to attend and ask questions about challenges.
Register Your Partial or Complete Team
Use the Team Registration Form to register your partial or complete team. We encourage early registration even if your team isn’t complete — to help others connect and join. In the form, you’ll be able to indicate whether you’re open to additional members (teams can have up to 5 people) and what skills you’re looking for. We’ll share a spreadsheet of open teams in our MLM25 Slack channel; join the Data Science Hub Slack to access this channel.
The deadline to register your team is Thursday, Sept. 18 at 11:59 PM (one week after kickoff).
Advanced Reasoning Corpus (ARC) 2025

Summary: This is an advanced challenge focused on solving abstract visual reasoning tasks with minimal data. Success often requires models that can generalize, reason step-by-step, or explore possible transformations—approaches that go beyond standard deep learning. Solutions may involve foundation models, chain-of-thought prompting, agent-like behaviors, or custom programmatic reasoning.
Method areas: Few-shot learning, CoT prompting, agentic workflows, reinforcement learning-inspired search, pattern transformation logic.
Prerequisites: For highly advanced participants only. This challenge assumes a high degree of fluency with deep learning frameworks, foundation models, and programmatic reasoning techniques. Participants should be confident exploring advanced, open-ended modeling workflows with minimal guidance.
Brain-to-Text '25: Decoding Neural Signals to Speech
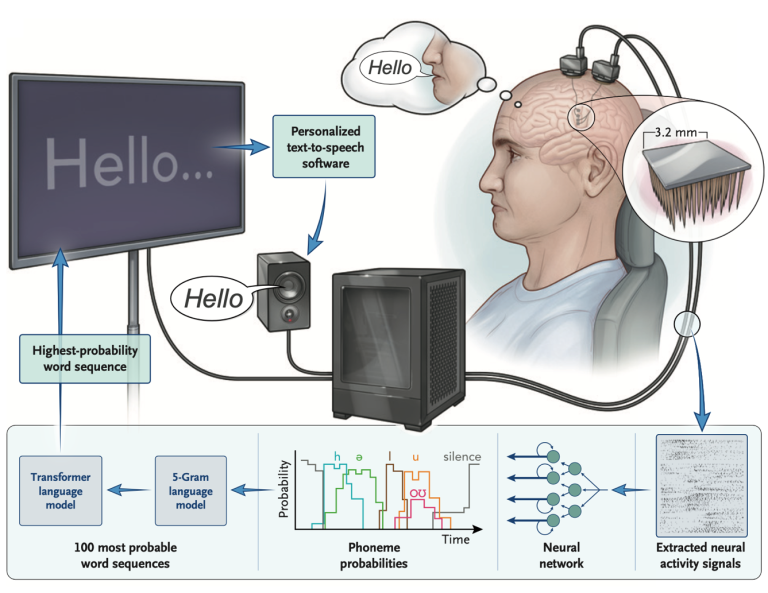
Summary: This advanced challenge tackles a real-world brain-computer interface (BCI) problem: decoding intended speech directly from neural activity. Using a dataset of over 10,000 labeled sentences and time series from 256 intracortical electrodes, participants will build models that map spiking activity to words. A baseline model decodes phoneme probabilities and passes them through a language model, but you’re encouraged to explore end-to-end architectures, test-time adaptation, or other decoding strategies. If you’re into speech, signal decoding, or sequence modeling, this is a rare chance to work with high-impact, cutting-edge data.
Method areas: Signal processing, time-series modeling, spiking neural data, sequence-to-sequence learning, speech decoding, RNNs or transformers, word error rate (WER) evaluation.
Prerequisites: Foundational knowledge of deep learning is expected. Some familiarity with signal processing or time-series modeling is recommended. No neuroscience background is required.
Cellular State Image Analysis

Summary: Using timelapse microscopy images of the human fungal pathogen Candida albicans, this challenge asks participants to identify transitions between cellular states — from filamentous (hyphal) biofilm growth to the release of yeast-form cells (dispersal). Ground truth will include hand-annotated and fluorescently tagged images, and participants will design image-based workflows that quantify both biofilm development and the timing and characteristics of dispersal. Bonus points for rich, interpretable outputs — such as tracking individual cells, quantifying biofilm structure, or modeling post-dispersal growth.
Method areas: Image classification or regression, texture analysis, segmentation, image-based quantification, temporal tracking, timelapse microscopy, custom metrics for biological events.
Prerequisites: Familiarity with image analysis tools is recommended. You don’t need prior experience in cell biology or fungal pathogens, but comfort working with low-resolution image data and designing custom evaluation workflows will be helpful.
Clustering the BioTrove Dataset: Unsupervised Learning for Biodiversity

Summary: The BioTrove dataset is a massive collection of biodiversity images curated from iNaturalist and annotated with detailed taxonomic metadata. In this challenge, you’ll work with a curated subset of BioTrove to explore unsupervised learning techniques that cluster images in biologically meaningful ways—recovering taxonomic structure at the species, genus, and family levels. Teams are encouraged to apply contrastive learning, autoencoders, or other deep learning methods to uncover structure in the data.
Method areas: Contrastive learning (e.g., SimCLR, SupCon), autoencoders, image embeddings, hierarchical clustering, CLIP-style models (optional), dimensionality reduction.
Prerequisites: Basic familiarity with neural networks and CNNs is expected. PyTorch experience is helpful. You don’t need to know contrastive learning or autoencoders beforehand, but these methods are encouraged and can be learned during the challenge.
CrisisCompanion: Creating a Mental Health Support Chatbot

Summary: Access to mental health support remains a critical global challenge, with millions unable to receive timely care due to cost, stigma, or availability barriers. While AI-powered chatbots show promise in providing 24/7 accessible support, developing systems that are both empathetic and safe requires careful integration of large language models. In this challenge, your task is to develop a mental health support chatbot that can engage in compassionate conversations.
Method areas: Generative AI, Text Analysis, Large Language Models (LLMs)
Prerequisites: Some familiarity with NLP concepts like tokenization and embeddings will be helpful. Prior experience with LLMs or deep learning isn’t required, but you should be ready to learn and collaborate—especially around prompt design or model selection. Tutorials and sample scripts will be provided.
Digit Recognizer: Getting Started with Deep Learning

Summary: This challenge offers a beginner-friendly entry point into deep learning using one of the most iconic datasets in machine learning: handwritten digit classification. Participants will build and train neural networks to recognize digits from image data, exploring core concepts like model architecture, loss functions, and evaluation. Teams are encouraged to implement solutions in multiple frameworks (e.g., PyTorch and Keras) to deepen their understanding and compare tooling. While this challenge is more study group than full-blown hackathon, it’s a strong foundation for more complex work in future semesters.
Method areas: Convolutional neural networks (CNNs), image preprocessing, classification metrics, and training workflows in PyTorch and/or TensorFlow/Keras.
Prerequisites: No prior deep learning experience is needed—this challenge is ideal for those new to neural networks. We recommend teaming up with others who share your learning goals and are open to trying multiple approaches.
MaveDB Amino Acid Substitution Prediction

Summary: Understanding the functional consequences of genetic variants is a cornerstone of modern genomics. Multiplexed Assays of Variant Effect (MAVEs) provide high-throughput measurements of how thousands of variants impact gene function, and MaveDB is a growing repository of these datasets, but it is still expensive and time-consuming to experimentally test every variant. In this challenge, your task is to develop a machine learning model that can predict the functional outcomes of amino acid substitutions.
Method areas: Regression models, foundation models, embeddings, zero-shot prediction, protein language models.
Prerequisites: A solid grasp of Python and machine learning fundamentals is expected. Familiarity with PyTorch and Hugging Face is highly recommended.
Store Sales: Time Series Forecasting

Summary: This challenge introduces core forecasting techniques through a real-world dataset: predicting future sales across multiple retail stores. Participants will explore temporal patterns, seasonality, and exogenous variables to build forecasting models that generalize well over time. While you’re welcome to focus on one approach, teams are encouraged to try multiple frameworks or methods (e.g., statsmodels, Prophet, deep learning-based approaches like RNNs or temporal CNNs) to better understand the trade-offs. This challenge is great for participants who want a structured way to explore time series modeling and build skills for applied forecasting problems.
Method areas: Classical forecasting (e.g., ARIMA), machine learning approaches (e.g., XGBoost), and deep learning methods for sequence prediction. Optional exploration of holiday effects and promotions.
Prerequisites: No prior time series experience is required—this challenge is suitable for newcomers looking to learn by doing. Tutorials will also be provided.
SurveyResponder Validation: Evaluating LLM Bias and Response Variation

Summary: This challenge supports early-stage development and validation of the SurveyResponder Python package—a tool for generating and analyzing synthetic survey data using large language models (LLMs). Participants will assess whether LLMs can produce realistic and demographically fair survey responses by comparing variation across models and personas. The focus is on designing and evaluating testing strategies, identifying bias, and comparing LLM outputs to known human response patterns. Work from this challenge may contribute to more trustworthy use of LLM-generated survey data in research.
Method areas: Inferential statistics (e.g., t-tests, ANOVA), response variability analysis, psychometric validation, LLM-based text generation.
Prerequisites: Familiarity with LLMs (e.g., via Ollama or AnywhereLLM) and basic survey research or psychometric principles is recommended. Experience with pandas and seaborn/matplotlib will be helpful for analysis and visualization.
WattBot: Estimating AI Emissions with Retrieval Augmented Generation (RAG)

Summary: AI systems can consume vast amounts of energy and water, but reliable emissions data remains hard to find and harder to trust. In this challenge, you’ll build a retrieval-augmented generation (RAG) system that extracts credible environmental impact estimates from peer-reviewed sources. Your model must output concise, citation-backed answers—or explicitly indicate when the evidence is missing. The goal: turn scattered academic knowledge into transparent, actionable insights for researchers, engineers, and policy makers.
Method areas: Retrieval‑augmented generation (RAG) workflows using LLMs, optical character recognition (optional) to better parse figures/tables from PDFs.
Prerequisites: Prior exposure to natural language processing (NLP) and deep learning fundamentals is recommended. No prior experience with large language models (LLMs), RAG, or Hugging Face is required, but you must be willing to learn!